
Az egyik nagy előnye, hogy az ember akadémiai kutatócsoport tagja, hogy hozzáférhet a NIIF szuperszámítógépeihez. A papíron leírt impozáns teljesítmény mutatók azonnal megdobogtatják egy magamfajta felhasználó szívét. Sajnos az örömbe sok üröm is keveredik, ha a tényleges felhasználásra kerül sor.
Regisztráció
A regisztrációs procedúra sokat egyszerűsödött, de márciusban, mikor a saját kérvényemet intéztem, ez kétfordulós meccs volt. Először projektszámot kellett igényelnem. Kitöltöttem egy papírt, aláírattam minden főnökömmel, akik igazolták, hogy én tényleg létezem, és tényleg kutató vagyok. Ezután még egyszer kitöltöttem egy nagyon hasonló papírt, ahol témaszámot igényeltem. A procedura nagyon hasonló volt. Kellett generálni egy ssh kulcsot és már kész is voltam.
Programok
A szuperszámítógépek használata hasonlít egy batyus lakodalomra: Étel-ital lesz elég, ha hoztok magatokkal. Szoftver lesz elég, ha fordítasz magadnak. Ez nem olyan problémás, egészen addig, amíg nem a függőségek függőségeit kell fordítani. Utána kicsit unalmassá válik. Én a Mira-t akartam futtatni, ezert felmásoltam egy statikusan linkelt binárist és azt használtam. Illetve próbáltam használni.
Üzemidő
Memória gondjaim voltak, ezért akartam a pécsi szuperszámítógépen dolgozni, de csak a kínlódás volt vele, ugyanis lépten-nyomon elérhetetlen volt a gép és a futó programok pedig elszálltak. Visszanéztem az ezzel kapcsolatos e-mailjeimet és az alapján készítettem ezt a grafikont:
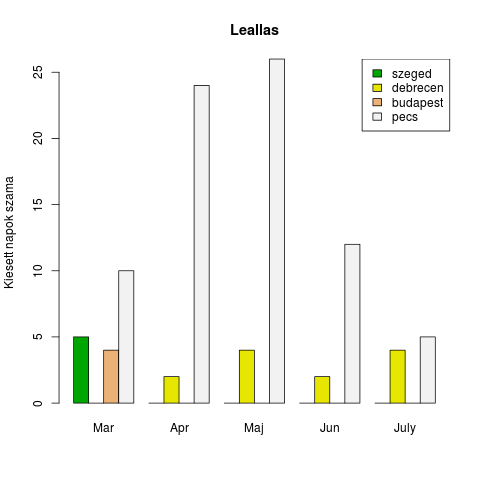
Egy hetet nem tudott folyamatosan menni a pécsi gép. Szerintem annak idején a Windows 95 jobban teljesített, nem? Áttértem a szegedire, ahol viszont nem jutottam sorra. (Illetve az egyik kiesés alkalmával csak a futó jobok szálltak el, a várakozási sor nem ürült, amitől az élre tudtam törni). A másik igencsak frusztráló dolog a jobütemező, ahol az idő folyamán egyre több korlátozást vezettek be. Egyik alkalommal nem voltam elég figyelmes és a job futásának hosszabb időt adtam meg, mint amennyi a felső határ volt. Nem kaptam hibaüzenetet, nem kaptam figyelmeztetést, semmit. Annyi tűnt fel, hogy van üres node, de én továbbra is a várakozási sorban dekkolok.
Mikor végre sorra kerültem, gyanúsan lassan futott a Mira. Rövid nyomozás után kiderítettem, hogy a félelmetes memória, CPU és sávszélesség mellett az IO műveletek röhejesen lassúak. (Emlékeztetőül: A bioinformatikai programok nagy fájlokat olvasnak és írnak). Álljon itt egy cseppet sem mélyreható, gyors tesz, mire is képesek a szuperszámítógépek:
| számítógép | olvasás | írás |
| szeged | 75,4 | 4,7 |
| deb | 204 | 8,8 |
| munkaállomás | 96,1 | 11 |
| otthoni | 66,1 | 15,1 |
A tesztet a jó öreg dd-vel csináltam:
dd if=/dev/urandom of=fajl # iras teszt
dd if=/dev/sda of=/dev/null # olvasas teszt
A teszt nem túl szofisztikált, de a célnak megfelel (meg nem ártott volna néhány ismétlés, de annyit nem ér az egész). A deb egy nagyteljesítményű számítógép, ami nem a NIIF tulajdonában van.
Végszó
Sajnos semmi hasznosat nem tudtam kezdeni a hazai szuperszámítógépekkel. Végül úgy végeztem el a munkát, hogy lecsökkentettem a readek számát, hogy beleférjen 70GB memóriába, majd lefuttattam egy erre alkalmas gépen.
